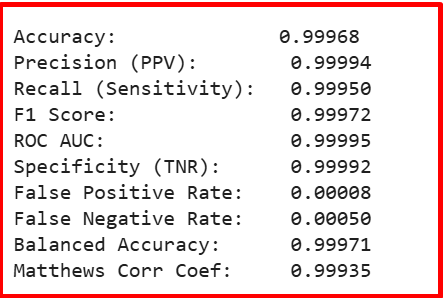
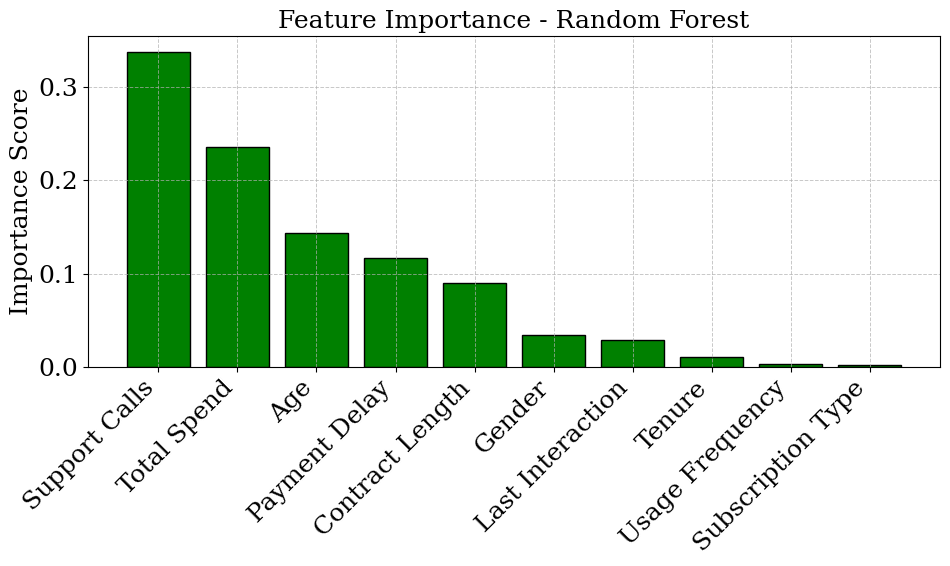
এক বৈপ্লবিক সভ্যতার পথে
মানবসভ্যতার এই দীর্ঘযাত্রা প্রকৃতপক্ষে এক মহাজাগতিক গল্পের
ক্ষুদ্র কিন্তু অনন্য অধ্যায়। কোটি কোটি বছরের তারামৃত্যু থেকে জন্ম নেওয়া অণু-পরমাণু
একদিন প্রাণের স্পন্দন এনেছিল পৃথিবীতে। সেই প্রাণ থেকে উদ্ভব হয়েছিল ভাবনা, কল্পনা,
আর এই বিশাল সৃষ্টিকে জানার এক অদম্য তৃষ্ণা। হাজার বছর ধরে মানুষ প্রকৃতিকে বুঝতে
ও শাসন করতে শিখেছে, আগুনের আলোয় রাতকে জয় করেছে, চাকার আবিষ্কারে দূরত্ব মুছে ফেলেছে,
বিদ্যুৎ ধরে রেখেছে তারের মধ্যে। তারপর কম্পিউটার এসেছে, আমাদের গণনার সীমা ভেঙে নভোমণ্ডল
থেকে জেনোম পর্যন্ত সবকিছু মানচিত্রে বেঁধেছে। এখন এমন এক সন্ধিক্ষণে দাঁড়িয়ে, যেখানে
আমরা তৈরি করেছি কৃত্রিম বুদ্ধিমত্তা, যা শুধু গণনা নয়, শিখতে পারে, সিদ্ধান্ত নিতে
পারে, এমনকি নিজের মতো করে ব্যাখ্যা গড়ে তুলতে পারে। এটি কেবল আরেক প্রযুক্তি নয়।
এটি মানুষের তৈরি আরেক “চেতনা”-র
দিকে হাত বাড়ানো এক আধ্যাত্মিক অভিযাত্রা, যেখানে মানুষ তারই প্রতিচ্ছবি সৃষ্টি করে
আবার নিজেকেই নতুন করে খুঁজে পাচ্ছে।
বর্তমান পৃথিবী: কৃত্রিম
বুদ্ধিমত্তার ছায়ায়
আজ সকালে ঘুম থেকে উঠে আপনার মোবাইলে যে নিউজ ফিড খুললেন,
তা AI নির্ধারিত। আপনি গুগলে কিছু সার্চ করলেন, তার ফলাফল AI-এর বাছাই করা। গুগল ম্যাপ
আপনাকে কোন রাস্তা দিয়ে যাবেন বলছে, তা AI ট্রাফিক অ্যানালাইসিস করে বলে। আপনি ইউটিউবে
কোন ভিডিও দেখছেন, ফেসবুকে কোন পোস্ট আপনার সামনে আসছে সব AI আলগরিদমের কাজ।
শুধু ব্যক্তিগত জীবনে নয়, শিল্পক্ষেত্রেও AI বিপ্লব এনেছে।
Predictive Maintenance থেকে Supply Chain Optimization, AI এমন সিদ্ধান্ত নিচ্ছে যা
আগে শত শত মানুষের অভিজ্ঞতা ও বিশ্লেষণের ওপর নির্ভর করতো। কৃষিতেও AI ক্রমশ ঢুকছে।
ড্রোন ও স্যাটেলাইট চিত্র বিশ্লেষণ করে জমির আর্দ্রতা, ফসলের স্বাস্থ্য দেখা হচ্ছে।
AI মডেল বলছে কখন কীটনাশক প্রয়োজন, কখন কী সার প্রয়োগ করতে হবে।
স্বাস্থ্যখাতেও AI বড় পরিবর্তন আনছে। রোগের প্রাথমিক স্ক্রিনিং,
যেমন চক্ষুর রোগ বা ক্যান্সার শনাক্তকরণ, এখন AI মডেলগুলো প্রায় সমপর্যায়ের বা কখনো
ডাক্তারদের থেকেও বেশি সঠিক। হাসপাতালের ইলেক্ট্রনিক হেলথ রেকর্ড বিশ্লেষণ করে কোন
রোগীর ICU প্রয়োজন হতে পারে, তা আগেই অনুমান করছে AI। COVID-19 এর সময় আমরা AI দিয়ে
ভাইরাস স্প্রেড মডেলিং, ভ্যাকসিন ক্যান্ডিডেট ডিজাইন সব করেছি।
আগামীর পৃথিবী: কোথায়
যাচ্ছি আমরা?
আমি যে কথাটি প্রায়ই বলি, তা হলো আমরা "মিশ্র বুদ্ধিমত্তার
সভ্যতা"-র দিকে যাচ্ছি। মানুষ আর মেশিন আলাদা থাকবে না, বরং একটি সমন্বিত বুদ্ধিমত্তার
পরিবেশ তৈরি হবে। একজন ডাক্তার তার অভিজ্ঞতা আর অন্তর্দৃষ্টি নিয়ে সিদ্ধান্ত নেবেন,
কিন্তু AI তাকে বলবে বিশ্বের কোটি কোটি রোগীর উপাত্ত বিশ্লেষণ করে সবচেয়ে সম্ভাব্য
রোগটা কী হতে পারে। একজন আইনজীবী মামলার রায় পড়বেন, কিন্তু AI বলবে ২০০ বছর ধরে হওয়া
অনুরূপ মামলায় কী ফলাফল হয়েছে। একজন শিক্ষক শিশুর শেখার ধরন বুঝতে তার জন্য AI কাস্টমাইজড
কনটেন্ট তৈরি করবে।
এতে সবচেয়ে বড় পরিবর্তন হবে কর্মসংস্থান ও দক্ষতার চিত্রে।
প্রথাগত অনেক কাজই অদৃশ্য হয়ে যাবে। যেটি থাকবে, সেটি হবে মানুষের সৃজনশীলতা, জটিল
সমস্যা সমাধান, সমবেদনা এবং নেতৃত্ব ভিত্তিক কাজ যেমন, টেক্সটাইল ইন্ডাস্ট্রিতে AI
ডিজাইন তৈরি করতে পারে, কিন্তু নতুন ফ্যাশন ট্রেন্ড বা সংস্কৃতি বোঝার ক্ষমতা মানুষের।
কৃষিকাজে AI বলবে কোন মাঠে কোন ফসল হবে, কিন্তু স্থানীয় মাটি, মানুষ আর প্রাকৃতিক
ইঙ্গিতের মিশ্রণ মানুষই সবচেয়ে ভালো ধরতে পারে।
একইসঙ্গে মানবজাতি বড় নৈতিক চ্যালেঞ্জেও পড়বে। যদি AI সিভিল
কোর্টের বিচারক হয়ে যায়, তাহলে ন্যায়বিচার কেবল অ্যালগরিদমের হাতে ন্যস্ত হবে? যদি
স্বচালিত অস্ত্র (killer drones) সিদ্ধান্ত নেয় কাকে হত্যা করবে, তখন দায়ভার কার?
যদি মানুষের ব্যক্তিগত তথ্য AI বিশ্লেষণ করে, তাহলে গোপনীয়তা কতটা থাকবে? এই প্রশ্নগুলোর
উত্তর খুঁজতে আমাদেরকে বিজ্ঞান, দর্শন, নীতি ও আইন একসঙ্গে নিয়ে কাজ করতে হবে।
বাংলাদেশের প্রেক্ষাপটে
আমরা বাংলাদেশের প্রেক্ষাপটেও দেখতে পাচ্ছি, ধীরে ধীরে
AI প্রবেশ করছে। ব্যাংকগুলো কাস্টমার রিস্ক প্রোফাইলিং করছে। স্বাস্থ্যখাতে টেলিমেডিসিন
সিস্টেমগুলো এখন রোগীর উপসর্গ থেকে ডায়াগনোসিস সাজেস্ট করছে। এমনকি আমাদের কৃষি বিশ্ববিদ্যালয়গুলোর
গবেষণায় AI মডেল ব্যবহার করে কোন অঞ্চলে কোন ফসল ভালো হবে, সেটি বের করা হচ্ছে। তবে
আমাদের মূল চ্যালেঞ্জ হচ্ছে, এখানে
যথাযথ দক্ষ মানবসম্পদ তৈরি করা। কেবল কিছু কোড শেখানোতে AI বোঝা যায় না। প্রয়োজন
গভীর স্ট্যাটিস্টিক্স, অপ্টিমাইজেশন, নেটওয়ার্ক থিওরি, এবং মেশিন লার্নিং-এর মৌলিক গাণিতিক
ধারণা।
আমাদের বিশ্ববিদ্যালয়গুলোর
ভূমিকা: প্রযুক্তি-মানবিকতার সেতুবন্ধন
আমাদের দেশের বিশ্ববিদ্যালয়গুলো এখনো AI এবং তথ্যপ্রযুক্তিকে
অনেকাংশে “অ্যাপ্লিকেশন লেভেল”
এ পড়ায়। অর্থাৎ শিক্ষার্থীরা শিখছে কোড, অ্যালগরিদম, কখনো কখনো মেশিন লার্নিং-এর
টুল। কিন্তু আসল যে বিশাল “সিস্টেমিক বোধ” দরকার, যেখানে প্রযুক্তি, সমাজ, অর্থনীতি, নৈতিকতা এবং মানবিকতা
একাকার হয়ে যায়, সেটি আমরা কম শিখছি। এই জায়গায় আমাদের বিশ্ববিদ্যালয়গুলোর ওপরই
সবচেয়ে বড় দায়িত্ব। আমাদের সিলেবাসে শুধুমাত্র Python, Data Structure বা
Neural Network এর হিসাব নয়; আমাদের প্রয়োজন AI এর সামাজিক প্রভাব,
Bias-Variance Tradeoff এর সাথে নৈতিকতার যোগ, Privacy এবং ডিজিটাল অধিকার নিয়ে আলাদা
কোর্স। আমাদের দরকার Interdisciplinary Lab, যেখানে একজন কম্পিউটার ইঞ্জিনিয়ার বায়োকেমিস্টের
সাথে বসে ক্যান্সার প্রেডিকশন মডেল বানাচ্ছে, বা একজন পরিসংখ্যানবিদ কৃষি প্রকৌশলীর
সাথে Yield Optimization মডেল তৈরি করছে। আমাদের প্রয়োজন AI Ethics Board, যারা প্রতিটি
বড় প্রজেক্টের নৈতিক ও সামাজিক প্রভাব যাচাই করবে। আমরা চাইলে বাংলাদেশের AI চর্চাকে
কেবল “সফটওয়্যার সার্ভিস”
থেকে বের করে নিয়ে যেতে পারি জ্ঞাননির্ভর, বৈশ্বিক প্রভাবময় গবেষণা-এর দিকে। যেখানে
আমাদের ছাত্ররাই আগামীতে Nature, Science, NeurIPS, ICLR এর মতো বিশ্বমঞ্চে নিজেদের
দেশের সমস্যাকে গাণিতিক মডেল ও AI দিয়ে সমাধান করে দেখাবে।
মানুষ বনাম মেশিন: কে
আসলে কাকে নিয়ন্ত্রণ করছে?
অনেকেই AI দেখে আতঙ্কিত হন “রোবট আমাদের কাজ কেড়ে নেবে”, “AI সবকিছু নিয়ন্ত্রণ করবে”, এমনকি কেউ কেউ বলেন “এটি মানব সভ্যতার শেষ।” একদিক দিয়ে এই ভয় অযৌক্তিক নয়। কারণ আমরা ইতিমধ্যেই দেখি:
Social Media Algorithm আমাদের সময়, মনোযোগ, এমনকি মানসিক স্বাস্থ্য পর্যন্ত নিয়ন্ত্রণ
করছে। Credit Score AI অনেক ক্ষেত্রেই গরীব-প্রান্তিক মানুষকে ঋণ থেকে বঞ্চিত করছে।
Face Recognition AI প্রায়ই কালো বা বাদামী ত্বকের মানুষকে ভুলভাবে চিহ্নিত করছে।
কিন্তু আবার ইতিহাস বলে, মানুষ যখনই কোনো নতুন শক্তি পেয়েছে, আগুন, চাকা, বিদ্যুৎ, ইন্টারনেট প্রথমে কিছু বিপর্যয় ঘটেছে, কিন্তু শেষমেশ মানুষই সেটিকে
নিয়ন্ত্রণে এনেছে, সমাজের কল্যাণে ব্যবহার করেছে। আমাদের উচিত AI নিয়ে না আতঙ্কিত
হয়ে, না অন্ধভাবে মুগ্ধ হয়ে, বরং দায়িত্বশীল আশাবাদী হওয়া। আমাদের এমন AI বানাতে
হবে, যা মানুষের ন্যায্যতা আর মর্যাদা রক্ষা করবে। আমাদের AI প্রজেক্টগুলোতে
Transparent Testing রাখতে হবে, যেন আমরা বুঝতে পারি কোন Data Bias এসেছে, কোন
Model Decision অন্যায়। আমাদের চাই Explainable AI (XAI), যাতে একজন কৃষক বা একজন
গার্মেন্টস কর্মীও বুঝতে পারেন, AI
কেন তাকে এই সুপারিশ করল বা কেন ঋণ দিতে রাজি হলো না। সবচেয়ে বড় কথা, আমাদের শিক্ষা,
গবেষণা ও নীতি প্রণয়নে সর্বদা রাখতে হবে, প্রযুক্তি মানুষের জন্য, মানুষ প্রযুক্তির জন্য নয়।
আগামীর অর্থনীতি ও সমাজ:
নতুন বৈশ্বিক শ্রেণী বিভাজন?
AI এবং অটোমেশনের ফলে যেসব সহজ পুনরাবৃত্তিমূলক কাজ (যেমন
ডেটা এন্ট্রি, লো-স্কিল ফ্যাক্টরি কাজ, ট্র্যাডিশনাল অ্যাকাউন্টিং) — এসব দ্রুত মেশিনে
চলে যাবে। ফলে দুই ধরনের মানুষের উদ্ভব হবে: যারা AI তৈরি, ব্যবস্থাপনা ও কৌশল নির্ধারণ
করবে এবং যারা AI দ্বারা প্রতিস্থাপিত হবে। এটি এক ভিন্ন রকম বৈষম্য তৈরি করবে। অর্থাৎ
যিনি AI বোঝেন, তার আয় বেড়ে যাবে; আর যিনি বোঝেন না, তিনি পেছনে পড়বেন।
আগামী পৃথিবীর অর্থনীতি হবে "data-driven
predictive economy"। Supply Chain থেকে শুরু করে স্বাস্থ্যনীতি পর্যন্ত রিয়েল-টাইম
এআই এনালাইসিস দ্বারা চলবে। কোম্পানিগুলো আপনাকে পণ্য বেচার আগে আপনার মনোভাব বুঝে
যাবে। এমনকি শহরগুলোর smart grid, পানি সরবরাহ, ট্রাফিক সবই AI দ্বারা নিয়ন্ত্রিত
হবে।
শিক্ষা: কীভাবে প্রস্তুত
করব আমাদের প্রজন্মকে
আমার বিশ্বাস, সবচেয়ে গুরুত্বপূর্ণ যুদ্ধ এখন ক্লাসরুমে।
আগের প্রজন্মের মতো শুধু গাণিতিক সূত্র মুখস্থ করলে হবে না। আমাদের দরকার:
Critical Thinking: কেন মডেল এই সিদ্ধান্ত নিল, সেটি প্রশ্ন
করতে শিখতে হবে।
Interdisciplinary Approach: একজন কম্পিউটার ইঞ্জিনিয়ারকে
বুঝতে হবে বায়োলজি, একজন কৃষিবিদকে শিখতে হবে ডেটা অ্যানালিটিক্স।
Ethics & Soft Skills: AI decision কে challenge করবে,
সেটির নীতি নির্ধারণ করবে কে? এগুলো শিখতে হবে।
বাংলাদেশের স্কুল-কলেজের পাঠ্যক্রমে এখন থেকেই
computational thinking, ডেটা লিটারেসি, AI-এর ভিত্তি আনার সময় এসেছে।
ভবিষ্যতের পৃথিবী: কিছু
কল্পনা
চলুন কিছু ভিজ্যুয়াল দৃশ্য কল্পনা করি—
- গ্রামের একটি ছোট হেলথ ক্লিনিকে একজন নারী রোগীর শরীরের ডাটা, AI বিশ্লেষণ করে প্রাথমিক ক্যান্সার শনাক্ত করল, ডাক্তার তাৎক্ষণিক সিদ্ধান্ত নিলেন।
- এক কৃষক তার মোবাইলের AI অ্যাপ খুলে বলল, “এই জমিতে এবার পাটের পরিবর্তে সূর্যমুখী লাগান, মাটি ও আবহাওয়া সেটাই বলছে।”
- এক শিশু রাত ৯টায় ঘুমের আগে AI ‘কাহিনিসঙ্গী’ থেকে গল্প শোনে, যার কাহিনী তার দিনভর আনন্দ-দুঃখ থেকে তৈরি
হয়েছে।
- একটি বিশ্ববিদ্যালয়ের ল্যাবে গবেষকরা স্থানীয় রোগের জেনেটিক প্যাটার্ন AI দিয়ে বিশ্লেষণ করছে, যাতে আগামীর ভ্যাকসিন সরাসরি সেই অঞ্চলের জন্য সাজানো যায়।
- আদালতের কক্ষে বিচারক তার কেস ফাইল স্ক্যান করলে AI সিস্টেম শত শত পুরনো রায়ের নিখুঁত তুলনা দেখায়, যাতে ন্যায়বিচার আরেকটু নির্ভুল হয়।
- শহরের রাস্তায় চলাচল করা গাড়িগুলো স্বয়ংক্রিয়ভাবে একে অপরের সাথে যোগাযোগ করছে, AI ট্রাফিক সিগন্যাল ছাড়াই মানবসদৃশ ভদ্রতায় গতি কমিয়ে একে অপরকে পার হতে দিচ্ছে।
- আর কোনো একদিন হয়তো দূর মহাশূন্যে পাঠানো প্রোব আমাদের হয়ে নতুন গ্রহে AI দ্বারা কৃষি শুরুর প্রস্তুতি নিচ্ছে, পৃথিবীর মাটি থেকে নেওয়া গাছের ডিএনএ বুনে।
শেষ কথা
আমরা কি শুধুই spectator হয়ে বসে থাকব? না, আমাদের উচিত
এই পরিবর্তনের পাইলট হওয়া। আমাদের বিশ্ববিদ্যালয়, রিসার্চ ল্যাব, উদ্যোক্তা—সবাই মিলে এমন AI তৈরি করতে হবে যা আমাদের দেশের ভাষা, সংস্কৃতি,
অর্থনীতি ও ন্যায়বোধের সাথে সামঞ্জস্যপূর্ণ। আমরা চাই এমন recommendation systems যা বাংলা ভাষাভাষীদের সাংস্কৃতিক
প্রেক্ষাপট বুঝবে। এমন কৃষি AI যা বাংলাদেশি মাটি-জলবায়ুর ওপর ভিত্তি করে সুপারিশ
করবে। এমন হেলথকেয়ার AI যা স্থানীয় রোগ-জীবাণু, জীবনধারা জানে।
"আমরা আগুনের পিঠে চড়ে সভ্যতা গড়েছি,
বিদ্যুতের জাদুতে রাত জাগিয়েছি,
আর এখন সিলিকনের মস্তিষ্কে স্বপ্ন দেখছি।
আসুন আমরা সেই স্বপ্নকে মানুষের জন্যই বুনে তুলি।
যেখানে যন্ত্র আমাদের নয়, আমরা যন্ত্রের দিশারী।
যেখানে ন্যায়, মমতা আর সৃজনশীলতা হবে সভ্যতার কেন্দ্রবিন্দু।
এগিয়ে আসুন, চলুন আমরা AI-কে মানবতার কাব্য বানাই।"
বাংলাদেশের মাটির মানুষ চরম পরিশ্রমী, প্রবল সহিষ্ণু। আমাদের
তরুণরা বিশুদ্ধ আগ্রহ নিয়ে শিখতে চায়, নতুন কিছু তৈরি করতে চায়। যদি আমরা তাদের
হাতে সঠিক দিকনির্দেশনা, টুল, এবং সবচেয়ে বড় কথা নৈতিকতা ও মানবিকতা দিতে পারি, তাহলে তারাই হবে আগামী বিশ্বের AI নেতৃত্বের প্রধান সৈনিক।
আমাদের বিশ্ববিদ্যালয়, শিক্ষক, গবেষক, নীতি নির্ধারক সবাই মিলে যদি একযোগে এগিয়ে
আসি, তাহলে বাংলাদেশ কেবল “চতুর্থ শিল্প বিপ্লব” এর যাত্রী হবে না, বরং এই বিপ্লবের গন্তব্য নির্ধারণকারীও
হবে।

মোঃ আলমগীর হোসেন
Instructor, Skill Morph
Lecturer, Dept. of CSE, State University of Bangladesh